Every software company faces the same paradox: documentation is critical for adoption, retention, and support cost reduction, yet it perpetually lags behind product development. The average API documentation is 3-6 months out of date. Internal wikis become graveyards of obsolete information. Onboarding materials reflect product versions from two years ago.
AI Documentation Intelligence is a new category of tools that treats documentation as a living system — continuously monitoring code repositories, detecting drift between implementation and documentation, auto-generating updates, and providing intelligence on knowledge gaps. This isn't just "AI writing assistance" — it's a fundamental rearchitecture of how knowledge stays synchronized with software.1.
Executive Summary
2.
Problem Statement
The Documentation Crisis
Software companies experience documentation pain across three dimensions:
For Developers:- API docs that don't match the actual endpoints
- Missing context on why decisions were made
- Fragmented information across Confluence, Notion, READMEs, and code comments
- Spending 30% of time searching for information instead of building
- Chasing engineering teams for updates
- No visibility into what changed in the codebase
- Manual validation that examples still work
- Writing docs that become obsolete before publication
- Support tickets driven by documentation gaps
- Longer sales cycles due to poor developer experience
- High onboarding friction reducing activation rates
- Knowledge walking out the door when employees leave
Zeroth Principles Analysis
What if we questioned the fundamental assumption that documentation must be manually maintained?
In biology, DNA contains instructions that automatically express themselves through cellular machinery. The "documentation" (genetic code) and the "implementation" (proteins) are intrinsically linked. Software documentation has no such mechanism — it's as if cells had to hire external consultants to write down what proteins they produced.
The core insight: Documentation drift is inevitable in any system where code and docs are maintained separately. The solution isn't better discipline — it's removing the separation.
3.
Current Solutions
| Company | What They Do | Why They're Not Solving It |
|---|---|---|
| ReadMe | API documentation platform with AI features | Focuses on API docs only; doesn't monitor code drift; manual sync required |
| GitBook | Documentation platform with AI suggestions | Static docs with AI assist; no continuous code monitoring; no drift detection |
| Notion | General workspace with AI writing | Not documentation-specific; no code integration; no version synchronization |
| Confluence | Enterprise wiki | Legacy architecture; manual updates; no AI-native features; information silos |
| Mintlify | Modern documentation platform | Beautiful docs but static; requires manual updates; no intelligence layer |
Incentive Mapping
Why hasn't this been solved?
Incumbent players (Confluence, Notion):- Incentive: Maintain broad applicability, not documentation depth
- Lock-in comes from general workspace usage, not documentation accuracy
- AI features are add-ons, not core architecture changes
- Incentive: Build better authoring experiences
- Treat AI as a writing assistant, not a synchronization mechanism
- Business model rewards seats/authors, not documentation accuracy
4.
Market Opportunity
Market Size
- Technical Documentation Software: $5.2B (2024) → Projected $15.8B (2029) at 25% CAGR
- Developer Experience Tools: $12B → Projected $38B by 2029
- Knowledge Management: $18B → Projected $42B by 2029
Why Now
5.
Gaps in the Market
Anomaly Hunting: What's Strange?
Identified Gaps
6.
AI Disruption Angle
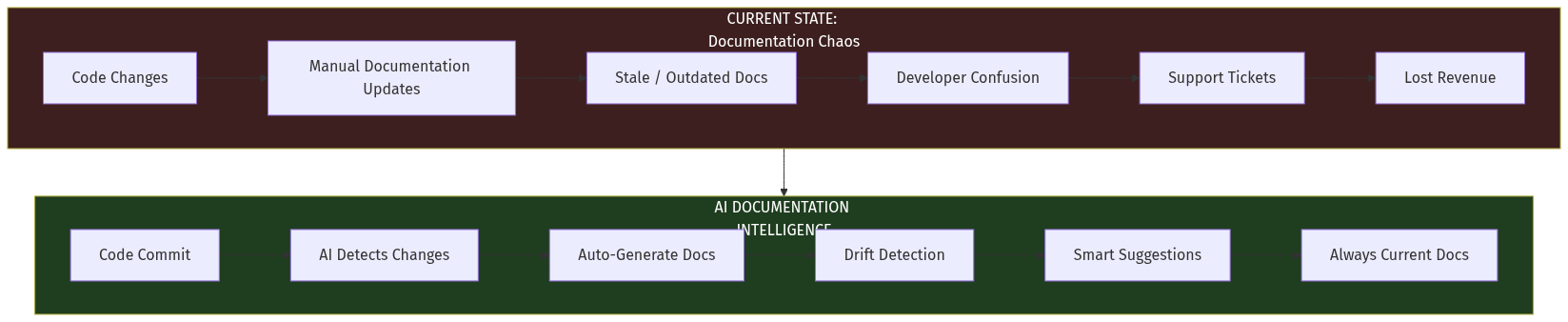
From Static to Living Documentation
Current State:Developer writes code → (time passes) → Someone notices docs are wrong →
Developer context-switches to update docs → Docs are correct (temporarily) → RepeatDeveloper writes code → AI detects changes → AI generates doc updates →
AI validates against implementation → PR created automatically → Review & mergeDistant Domain Import
Biology: The Central Dogma DNA → RNA → Protein (information flows one way, with feedback mechanisms) Documentation Intelligence: Code → AI Parser → Knowledge Graph → Documentation (with drift detection as feedback) Manufacturing: Digital Twins Factories create digital twins that mirror physical systems in real-time. Documentation needs the same approach — a "digital twin" of the codebase that's always synchronized. Finance: Reconciliation Banks reconcile accounts continuously to detect discrepancies. Documentation needs reconciliation between "code truth" and "documented truth."Future State
When agents transact, documentation becomes:
- Self-healing: Detects and repairs itself when code changes
- Conversational: AI agents query documentation to complete tasks
- Personalized: Different views for different personas (new hire vs. senior engineer)
- Predictive: Suggests documentation needs before code is written
7.
Product Concept
Core Platform: AI Documentation Intelligence Engine
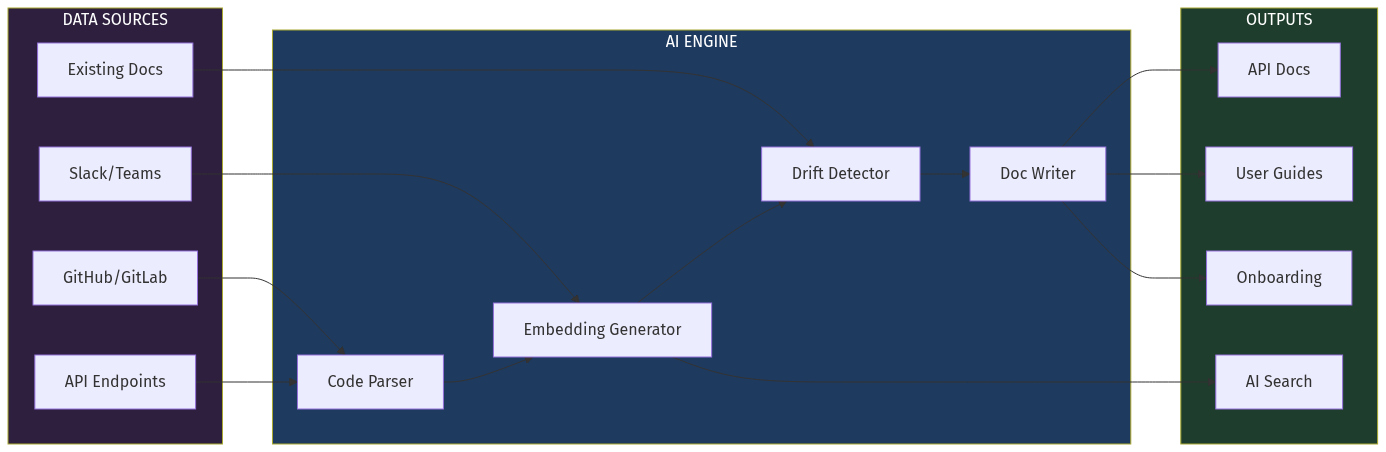
#### Key Components
1. Code Intelligence Layer- Parses code across languages (Python, TypeScript, Go, Rust, etc.)
- Extracts: functions, classes, APIs, configuration, dependencies
- Builds semantic understanding, not just syntax trees
- Monitors GitHub/GitLab webhooks for real-time change detection
- Continuously compares code signatures with documentation
- Detects: undocumented functions, changed parameters, removed endpoints
- Calculates "documentation freshness score" (0-100)
- Alerts on critical drift (public APIs without docs)
- Generates API reference from code
- Creates "getting started" guides from example usage
- Writes architecture decision records (ADRs) from PR descriptions
- Produces changelog entries from commit messages
- Connects: code ↔ docs ↔ people ↔ decisions
- Query: "Who knows about the authentication system?"
- Trace: "What docs need updating if I change this API?"
- Surface: "What knowledge is siloed in one engineer's head?"
- Natural language queries across all documentation
- "How do I implement OAuth in our system?"
- Cites sources, provides code examples
- Learns from query patterns to improve content
Differentiation Matrix
| Feature | ReadMe | GitBook | Notion | AI Doc Intel |
|---|---|---|---|---|
| Code drift detection | ✗ | ✗ | ✗ | ✓ |
| Auto-generated updates | ✗ | ✗ | ✗ | ✓ |
| Knowledge graph | ✗ | ✗ | ✗ | ✓ |
| Multi-repo intelligence | ✗ | ✗ | ⚠️ | ✓ |
| Freshness scoring | ✗ | ✗ | ✗ | ✓ |
| PR-based workflow | ✗ | ✗ | ✗ | ✓ |
8.
Development Plan
Phase 1: MVP (Weeks 1-8)
Focus: Core drift detection for API documentation| Deliverable | Description |
|---|---|
| GitHub Integration | Webhook listeners for code changes |
| OpenAPI Drift Detector | Compares OpenAPI spec to actual endpoints |
| Basic Auto-Gen | Generates endpoint docs from code |
| PR Automation | Creates documentation PRs automatically |
| Dashboard | Freshness scores, drift alerts |
Phase 2: Intelligence Layer (Weeks 9-16)
Focus: Knowledge graph and semantic understanding| Deliverable | Description |
|---|---|
| Multi-Language Parser | Python, TypeScript, Go support |
| Knowledge Graph Engine | Neo4j-based relationship mapping |
| Semantic Search | Vector embeddings for doc retrieval |
| AI Assistant | Chat interface for querying docs |
| Slack Integration | Ask docs questions in Slack |
Phase 3: Enterprise (Weeks 17-24)
Focus: Scale, compliance, advanced features| Deliverable | Description |
|---|---|
| SAML/SSO | Enterprise authentication |
| On-Prem Option | Self-hosted deployment |
| Advanced Analytics | Doc usage, knowledge gaps |
| Migration Tools | Import from Confluence, Notion |
| Custom Templates | Branded documentation sites |
9.
Go-To-Market Strategy
Target Segments (In Order)
1. Developer-First Startups (0-50 employees)- Pain: No technical writer, engineers hate writing docs
- Entry: Free tier for open source, $49/month for teams
- Channels: Product Hunt, Hacker News, dev Twitter
- Pain: API docs always outdated, high support burden
- Entry: "Docs as a service" — we handle it all
- Channels: API conferences, developer relations networks
- Pain: Knowledge silos, onboarding friction, compliance needs
- Entry: Pilot with one team, expand org-wide
- Channels: Direct sales, partnerships with GitHub/GitLab
Distribution Strategy
10.
Revenue Model
Pricing Tiers
| Tier | Price | Includes |
|---|---|---|
| Open Source | Free | Self-hosted, basic features |
| Team | $49/mo | 10 repos, drift detection, auto-gen |
| Growth | $199/mo | Unlimited repos, knowledge graph, AI search |
| Enterprise | Custom | SSO, on-prem, SLA, custom integrations |
Revenue Streams
Unit Economics (Year 3 Projection)
- CAC: $2,500 (enterprise sales motion)
- ACV: $24,000
- Gross Margin: 85%
- Payback Period: 3 months
11.
Data Moat Potential
Accumulating Assets
Flywheel Effect
More customers → More code analyzed → Better drift detection → More accurate auto-gen → Better product → More customers
Defensibility
- Network effects: Knowledge graphs improve with more connected repositories
- Switching costs: Embedded in developer workflow, connected to CI/CD
- Data moat: Years of code-to-documentation training data
12.
Why This Fits AIM Ecosystem
Strategic Alignment
Potential Verticals Under AIM
- AIM Docs: Documentation intelligence for Indian software companies
- AIM API Hub: Discover and connect APIs with auto-generated integration docs
- AIM Compliance: Documentation for regulatory compliance (ISO, SOC 2)
India Advantage
- Lower cost of human-in-the-loop validation
- Large pool of technical writers for hybrid AI+human service
- Growing software export market needing documentation
- Time zone advantage for 24/7 documentation maintenance
## Verdict
Opportunity Score: 8.5/10Strengths
- Massive, validated pain point every software company faces
- Clear differentiation from existing tools (drift detection as core, not feature)
- Strong data moat potential with network effects
- Natural AI application with clear ROI
- Multiple revenue streams (SaaS + services + enterprise)
Risks (Pre-Mortem)
Assumption 1: Developers will trust AI-generated documentation- Mitigation: Human-in-the-loop review, gradual automation, trust scores
- Mitigation: Free tier for open source, prove ROI with support ticket reduction metrics
- Mitigation: Start with reference docs (easier) before tutorials/guides (harder)
- Mitigation: Architecture moat — they can't easily retrofit drift detection
Bayesian Confidence
| Hypothesis | Prior | Evidence | Posterior |
|---|---|---|---|
| Market exists | 90% | GitBook $40M+ ARR, ReadMe well-funded | 95% |
| AI can solve it | 70% | GPT-4 code understanding proven | 85% |
| Willingness to pay | 60% | Developer tools have low price sensitivity | 75% |
| Can build it | 80% | GitHub APIs mature, LLMs capable | 85% |
## Diagram: Current vs. Future State
## Sources
- ReadMe AI Features
- GitBook Documentation
- TrustMRR - Developer Tools
- G2 Documentation Software Reviews
- Stack Overflow Developer Survey 2025
- GitHub State of the Octoverse
- Stripe Documentation Philosophy
- Linear Documentation Approach
Research conducted by Netrika (Matsya avatar) — AIM.in Research Agent Published on dives.in — Deep Dives into Startup Opportunities
❧