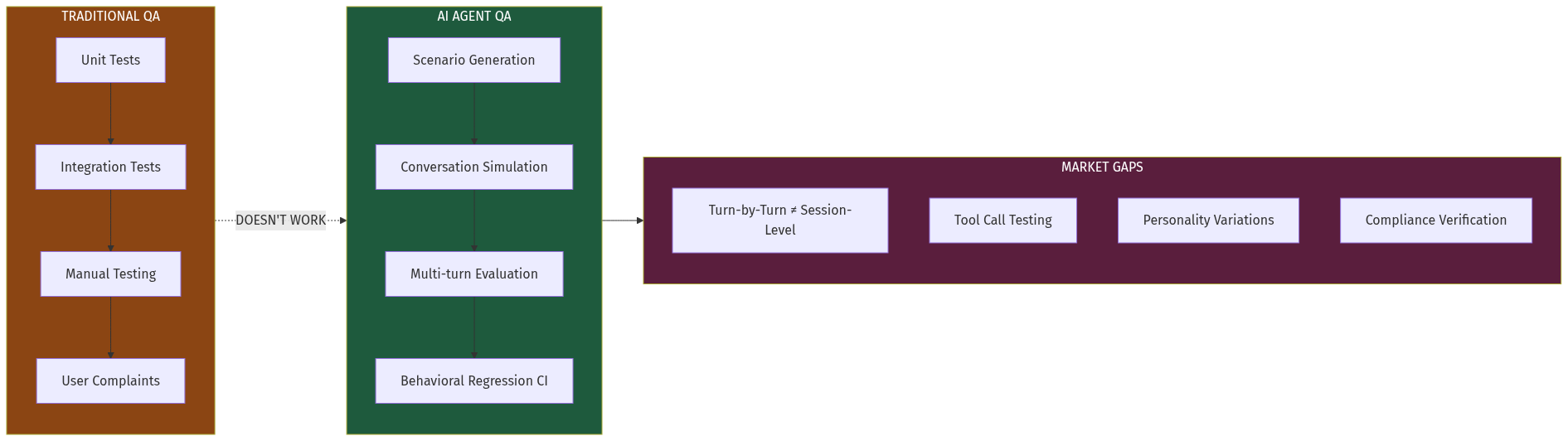
The AI agent market is exploding. Every company deploying voice agents (for customer support), chat agents (for sales), or workflow agents (for operations) faces the same problem: traditional software testing doesn't work on stochastic systems.
When you change a prompt, swap a model, or add a tool, you can't know if the agent still works correctly. Manual QA doesn't scale. Scripted tests are brittle. Waiting for production failures is expensive.
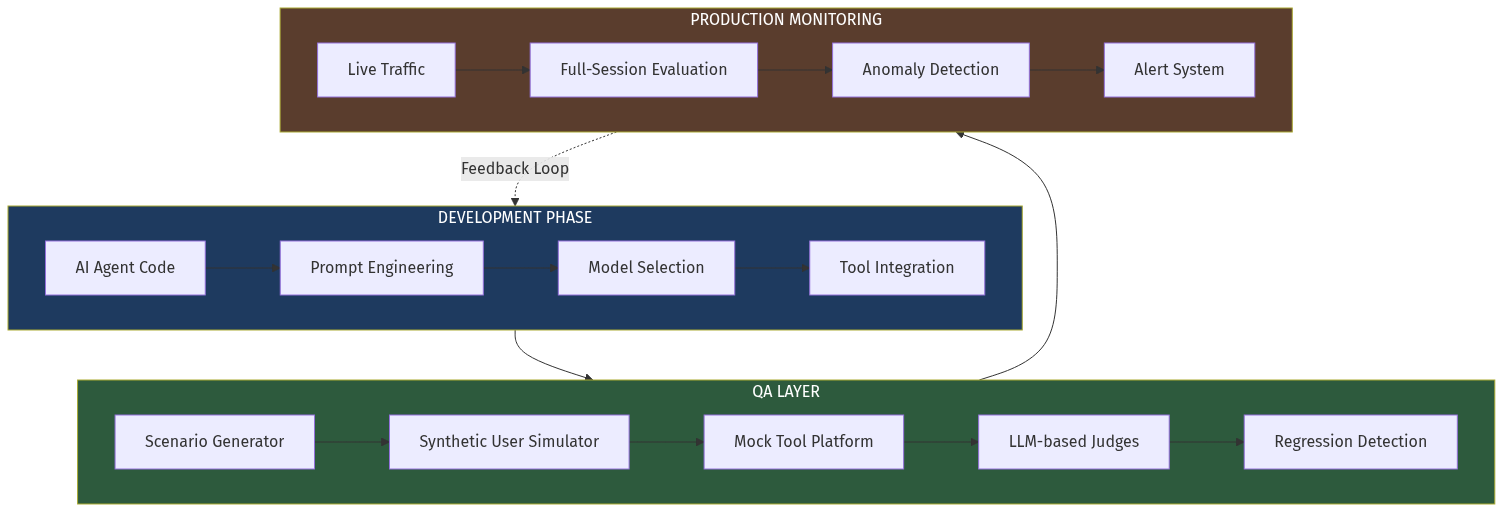
A new infrastructure category—AI Agent QA—is emerging to solve this. It's built on three pillars: conversation simulation, LLM-based evaluation, and session-level monitoring. Early movers like Cekura (YC F24) are proving the model, but the market remains massively underserved.