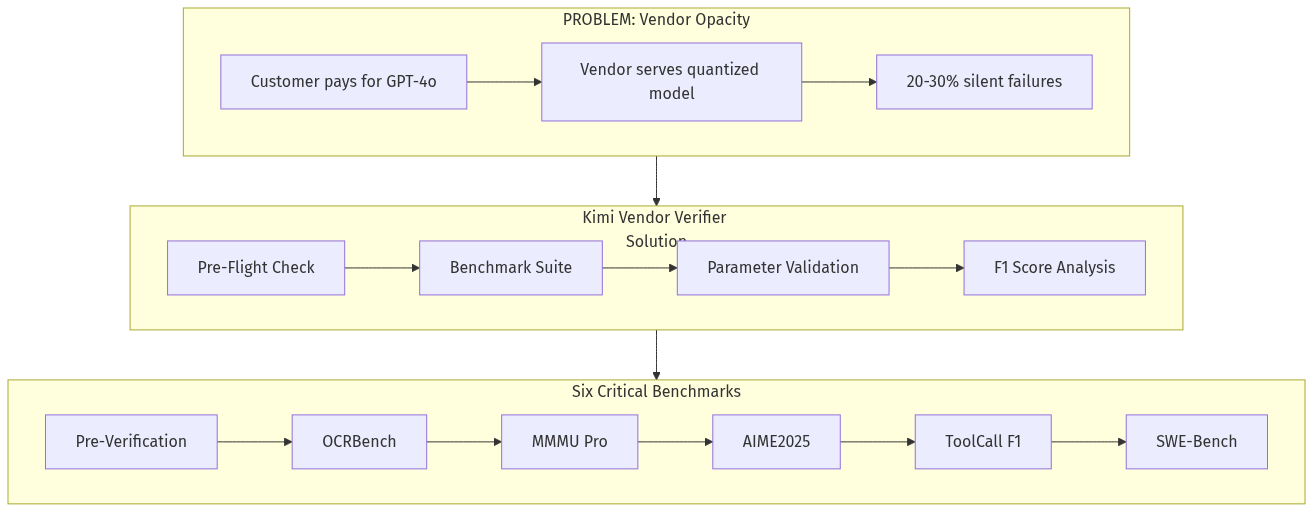
Moonshot AI just released the Kimi Vendor Verifier (KVV) — an open-source tool that verifies whether inference providers are actually serving the models customers paid for. The findings are damning: 20-30% of tool calls silently fail, benchmark scores vary wildly between official and third-party APIs, and quantization degrades quality without disclosure.
This reveals a systemic trust problem in the AI inference marketplace. Every company building AI agents depends on external API providers — but has no way to verify they are getting what they pay for. This creates a massive opportunity for a neutral verification marketplace.